李宏毅ml note
Intro
Traning
Function
使用 model:
其中, 表示 weight, 表示 bias
Loss function
表示:
Optimization
一般性方法: 梯度下降法(gradient descent)
- 选择起始点
- 计算梯度 ( 表示学习率 learning rate)
- 更新 w:
- b 作同样操作使 L 最小
More sophisticated models
多个 model 叠加
线性叠加
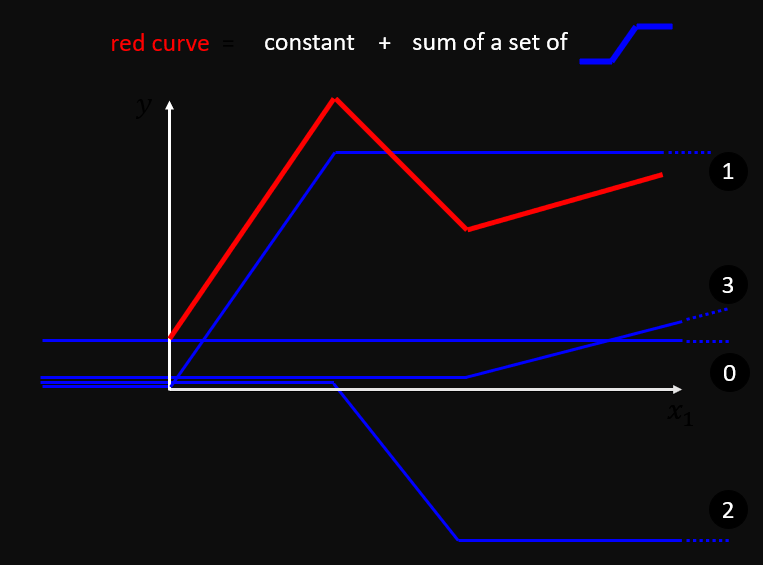
使用多个线性 model 叠加即可得到更为复杂的函数拟合曲线
Sigmoid func
使用 sigmoid 方程代替线性叠加可以得到所有的函数拟合,最终得到
即:
j: no. of features
i: no. of sigmoid
ReLu func
Loss
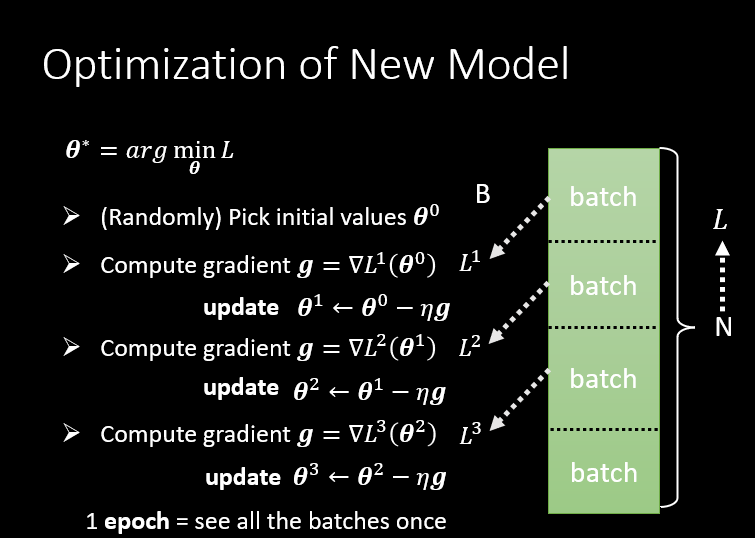
Optimization
梯度矩阵
在实际训练中,通常使用 batch 将原始数据集分解成不同的 batch 单独计算。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Lesereinの小木屋!
 微信
微信 支付宝
支付宝
相关推荐

2025-02-24
AI基础 笔记I
Intro Search: Formulation and Solution (s) Agent categories Rational agent Reflex agent Planning agent Have the model of how the world evolves. Optimal and replannning. Formulation Basic Elements of Search Problem State Space world state search state Successor Function Start state (to start the search) and goal test (to terminate the search) Solution Search graph A mathematical formulation of Search Problem: G={V, E} Nodes V: States IN State Space Edges/Arcs E: Successor Functions...
2025-03-24
AI基础 笔记II
CSP 概述 组成 A special subset of search problems. State is defined by variables XiX_iXi with values from a domain DDD (sometimes D depends on i). Goal test is a set of constraints specifying allowable combinations of values for subsets of variables 分类 Binary CSP: each constraint relates (at most) two variables. Binary constraint graph: nodes are variables, arcs show constraints. General-purpose CSP algorithms use the graph structure to speed up...
2025-03-23
CS188 Notes II
BN Inference Inference by enumeration Select the entries consisitent with the evidence. Sum out H (Hidden variables) to get joint of Query and evidence Normalize Variable Elimination Op 1: Join Factors Op 2: Eliminiate (Marginalizing Early) Op 3: Normalize Sampling Prior sampling 根据贝叶斯网络的拓扑排序,从根节点开始,按照条件概率分布逐步生成样本。 适用于贝叶斯网络的联合分布抽样,但可能导致低效样本(例如,许多样本不符合证据)。 Rejection sampling 先按照直接采样生成样本,然后拒绝不符合证据变量的样本。 适用于查询条件概率 P(X∣E)P(X | E)P(X∣E), Likelilhood weighting 固定证据变量 E,只对非证据变量进行采样。 E...
评论

